安全治理#数据安全#私有化部署
企业级 AI 数据安全的五层防线:从模型接入到审计追踪
2026年4月5日TokenStar 安全团队
围绕 TokenBase 私有化部署和管理指南中的安全主题,给出一套适合金融、制造、政企等场景的数据安全分层框架。
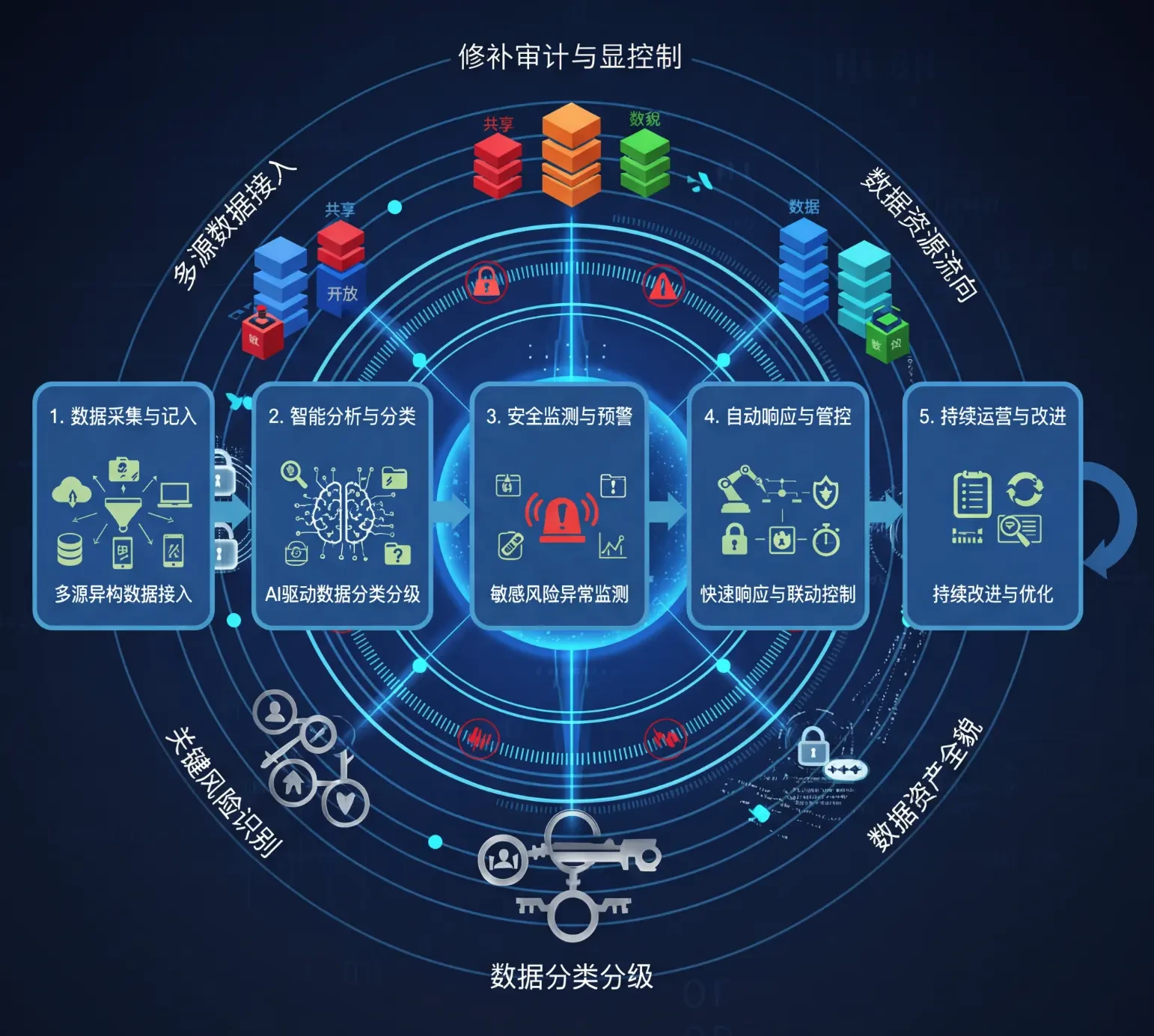
企业部署 AI Agent 时,最大的担忧从来不是“能不能回答”,而是“数据会不会失控”。一套成熟的企业级安全体系,必须覆盖模型、数据、权限、调用链路与审计追踪。
第一层:模型与运行环境边界
企业应首先明确哪些任务可以走云端模型、哪些必须在本地运行。涉及客户资料、财务数据、研发文档、内部制度的场景,优先采用本地模型或私有网络出口,以确保原始数据不外流。
- 为不同业务场景设置模型白名单与路由策略。
- 限制测试环境直接访问生产知识库与真实客户数据。
- 将推理服务、向量检索与业务系统置于分区网络中。
第二层:知识库与数据分级
AI 的回答质量依赖知识库,但风险也往往从知识库开始。建议将文档按公开、内部、敏感、核心四级管理,不同级别配置不同的索引策略、调用范围与导出权限。这样可以避免“低门槛账号读取高敏内容”的常见问题。
| 数据层级 | 典型内容 | 建议控制 |
|---|---|---|
| 公开级 | 官网资料、宣传文档 | 可用于公开问答与营销内容生成 |
| 内部级 | 流程文档、培训材料 | 仅授权员工和业务 Agent 访问 |
| 敏感级 | 客户合同、财务数据 | 细粒度权限+下载限制+脱敏 |
| 核心级 | 源码、配方、战略计划 | 默认不开放给通用 Agent,按任务审批 |
第三层:身份、权限与操作最小化
很多企业把 AI 当成一个统一入口,却忽略了它背后要继承企业原有的权限体系。正确做法是让 Agent “拿着角色权限去工作”,而不是让所有 Agent 使用同一个超级账号调用系统。
- 按岗位定义 Agent 可见数据范围。
- 按流程定义 Agent 可执行操作范围。
- 按审批定义高风险动作的人工确认机制。
第四层与第五层:调用链加固与全链路审计
一旦 Agent 开始连接 CRM、OA、数据库和外部 API,就必须记录“谁在什么时间、调用了什么工具、访问了哪些数据、产生了什么结果”。这不仅是安全要求,更是企业建立信任和持续优化的基础。
落地建议建议为每个关键 Agent 建立审计台账,至少保留输入摘要、命中的知识源、执行工具、输出结果和审批轨迹。这样既能满足审计,也方便复盘错误。