报告核心内容
医疗机构做 AI,第一步是数据分级
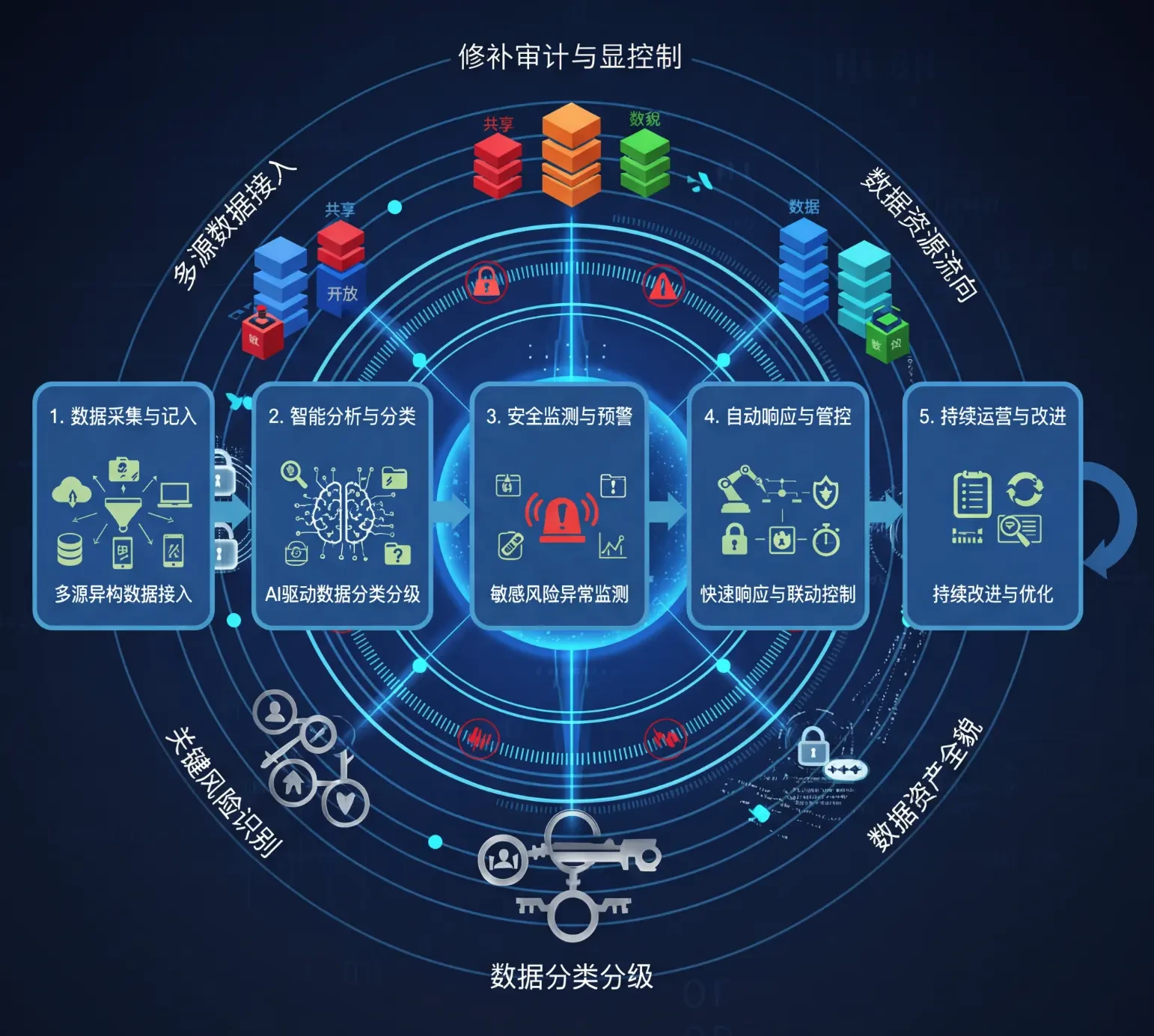
医疗机构拥有大量高敏感数据,且数据来源复杂、责任链条长。如果没有先完成数据分级、字段去标识化和访问权限设计,就很难让任何 AI 应用进入可信运行状态。
报告建议把病历、影像、检验、科研与运营数据分别纳入不同治理策略,避免一刀切管理导致项目推进缓慢。
区分临床高敏数据、科研数据与运营数据
为敏感字段建立脱敏、加密与审计策略
让业务负责人参与数据准入与使用边界定义
最适合优先推进的医疗 AI 场景
在治理能力尚未完全成熟前,院内知识助手、科研文献检索、问诊准备和非诊疗流程辅助更适合作为优先试点。这些场景既有明确效率收益,也更容易建立责任边界。
而直接面向诊疗决策的场景,应在取得更高治理成熟度后逐步推进,并保留强制人工确认。
院内知识助手可优先覆盖制度、路径与药械说明
科研检索适合率先验证知识整合与摘要能力
问诊辅助更适合做“信息整理”而非“诊断替代”
可信应用的关键,在于持续审计与复盘
医疗 AI 项目不能只在上线前做一次审查,更重要的是建立持续抽样、异常上报和版本复盘机制。任何高风险输出都需要能追溯到数据来源、模型版本和审核责任。
只有把这些能力做成日常机制,AI 才能真正成为医疗组织可控、可信的长期能力。
对关键输出建立抽样复核和异常上报流程
记录模型版本、知识来源与审核动作
定期复盘误判样本,持续更新风险控制策略