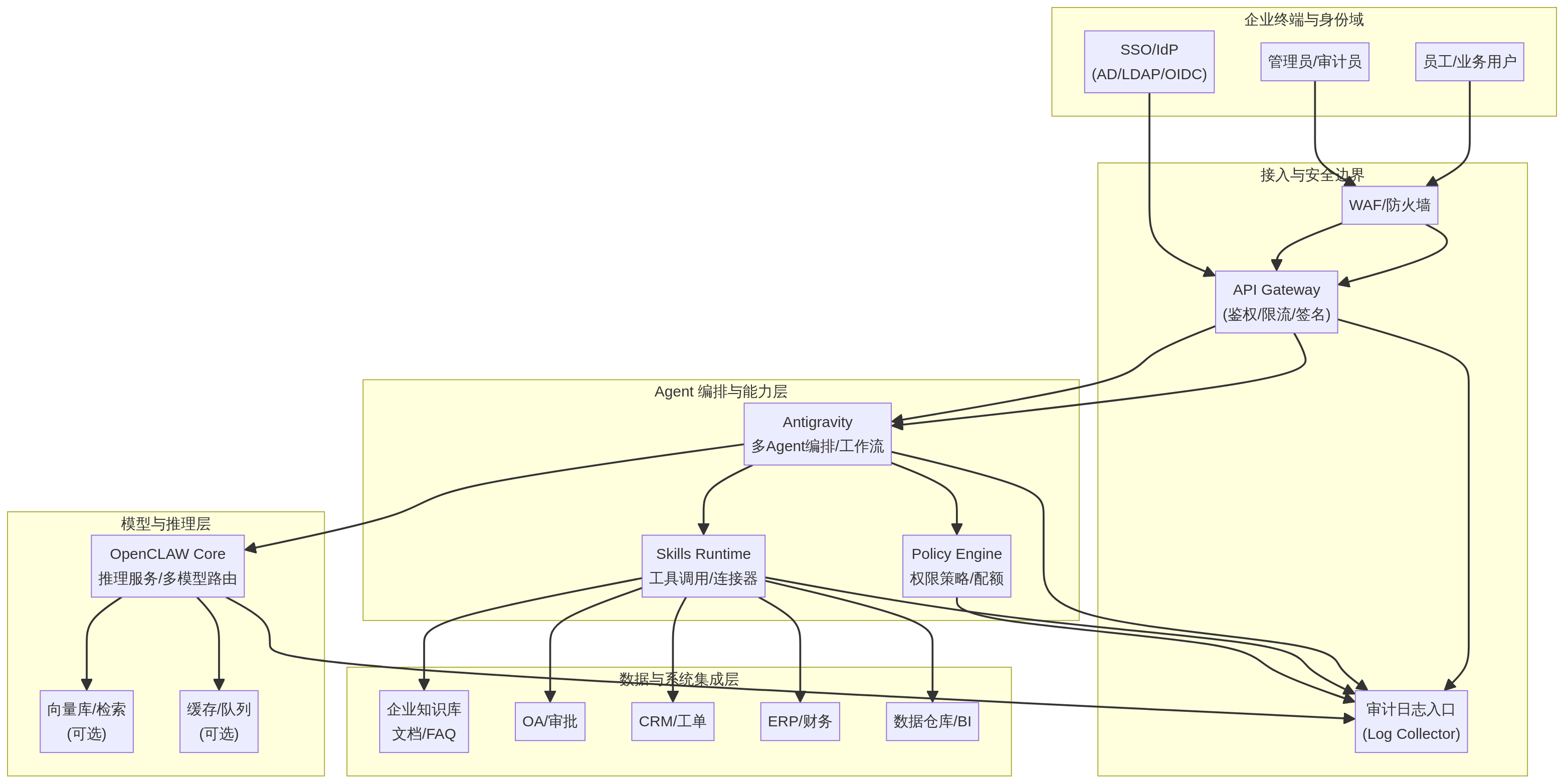
报告核心内容
一、技术全景:2024—2026 大语言模型的能力跃迁
2024—2026 年是大语言模型技术发展史上最为激荡的三年。如果说 2023 年 GPT-4 的发布标志着 LLM 从"能用"迈入"好用",那么 2024—2026 年间的技术演进则意味着 LLM 正从"好用"走向"可靠"和"高效"。这一时期的核心技术突破不再仅仅体现在参数规模的扩大,而是体现在模型架构创新、训练范式转移、推理效率优化和多模态能力融合四个维度的系统性进步。
在模型能力的绝对水平上,2026 年的旗舰模型较 2024 年初实现了质的飞跃。OpenAI 的 GPT-5(2025 年底发布)在 MMLU 基准上达到 92.3%(GPT-4 为 86.4%),在 GPQA Diamond(研究生级别科学推理)上达到 78.4%(GPT-4 为 59.4%),在 HumanEval 代码生成上达到 96.2%(GPT-4 为 67.0%),在 MATH 数学推理上达到 89.7%(GPT-4 为 52.9%)。Anthropic 的 Claude 4(2026 年 Q1 发布)在长文档理解和复杂指令遵循上建立了新的行业标杆——其在 RULER 128K 长上下文基准上的表现首次超越人类专家基线。Google DeepMind 的 Gemini 2.5 Pro 则凭借 100 万 token 的超长上下文窗口和原生多模态能力,在跨模态推理任务上领先。Meta 的 Llama 4 系列(Maverick 和 Behemoth)作为开源阵营的代表,在性能与效率的帕累托前沿上取得了令人瞩目的突破。
值得特别关注的是"推理模型"(Reasoning Model)这一全新品类的崛起。2024 年 9 月 OpenAI 发布 o1 模型标志着"推理时计算"(test-time compute)范式的正式确立——模型在生成最终答案之前,先进行多步骤的"思维链"推理,通过消耗更多推理计算来换取更高的准确性。到 2026 年,推理模型已形成完整的产品线:OpenAI 的 o3/o4-mini、Anthropic 的 Claude 4 Extended Thinking、Google 的 Gemini 2.5 Flash Thinking、DeepSeek 的 R1 等。这些模型在数学、编程、科学推理等需要深度思考的任务上,性能远超传统的"直觉式"生成模型。例如,o3 在 ARC-AGI 基准(衡量模型泛化推理能力的"AI 智商测试")上达到 87.5% 的得分,而 GPT-4 仅为 5%。推理模型的兴起从根本上改变了 LLM 的应用范式——从"快速生成"到"深度思考",也对推理基础设施提出了全新的算力需求。
Scaling Law(规模定律)的演进是理解 LLM 技术走向的核心框架。2020 年 Kaplan 等人首次提出的 Scaling Law 表明,模型性能与参数量、训练数据量和计算量之间存在可预测的幂律关系。这一定律在 GPT-3 到 GPT-4 的演进中得到了充分验证。然而,到 2025 年,纯粹依靠"堆参数"和"堆数据"的 Scaling 路径开始遭遇瓶颈——高质量文本数据的存量正在被快速消耗,据 Epoch AI 估算,到 2028 年全球高质量文本数据将被训练"耗尽"。面对这一挑战,业界探索出三条新的 Scaling 路径:一是数据质量 Scaling——通过合成数据生成、数据筛选与清洗技术提升训练数据的有效信息密度;二是推理时计算 Scaling——即上述推理模型范式,通过增加推理阶段的计算量来提升结果质量;三是后训练 Scaling——通过更精细的 RLHF(人类反馈强化学习)、DPO(直接偏好优化)和 Constitutional AI 等对齐技术,在不增加预训练规模的情况下持续提升模型的有用性和安全性。
多模态融合是 2025—2026 年 LLM 技术演进的另一个核心方向。早期的 LLM 只处理文本,而 2026 年的旗舰模型已普遍具备原生的文本、图像、音频、视频理解与生成能力。GPT-5 支持图像和音频的原生输入与输出;Gemini 2.5 Pro 从设计之初就是多模态原生架构,在视频理解任务上表现尤为突出;Claude 4 在文档与图表理解上建立了行业标杆。多模态能力的成熟使得 LLM 的应用范围从纯文本场景大幅扩展到医疗影像分析、工业视觉检测、视频内容理解、多模态文档处理等领域。据 IDC 数据,2026 年全球多模态 AI 应用市场规模约 180 亿美元,预计到 2028 年将增长至 520 亿美元,CAGR 超过 70%。
二、推理优化:成本下降 90% 背后的四大技术路线
如果说模型能力的提升打开了 LLM 的"天花板",那么推理成本的急剧下降则打开了 LLM 的"地板"——让大模型从少数顶尖企业的专属工具变成每一家企业都用得起的通用能力。据信悦数科统计,2024 年初至 2026 年 Q1,GPT-4 级别能力的推理成本下降超过 90%:从约 $30/百万输入 token 降至 $2.5/百万输入 token(以 OpenAI API 定价为基准)。开源模型的推理成本更低——使用 Llama 4 Maverick 在主流云平台上的推理成本约为 $0.15—$0.30/百万 token。这意味着处理一篇 5000 字的文档,成本不到 0.001 美元。
推理成本的骤降背后是四大技术路线的系统性突破。第一条路线是 MoE(Mixture of Experts,混合专家)架构。传统的 Dense Transformer 模型在每次推理时需要激活所有参数,而 MoE 架构通过引入路由机制,每次推理只激活一小部分"专家"参数,大幅降低了单次推理的计算量。Llama 4 Maverick 是 MoE 架构的典型代表——总参数量约 4000 亿(128 个专家),但每次推理仅激活约 360 亿参数(36 个专家),在保持 GPT-4 级别性能的同时将推理 FLOPs 降低约 65%。Google 的 Gemini 系列和 Mistral 的 Mixtral 系列同样采用 MoE 架构。MoE 的核心优势在于解耦了"模型容量"(由总参数量决定知识储备)与"推理成本"(由激活参数量决定计算开销),使得"又大又快"不再是矛盾。
第二条路线是模型蒸馏(Knowledge Distillation)。蒸馏的核心思想是用一个大模型("教师")的输出来训练一个小模型("学生"),使小模型在特定任务上逼近大模型的性能,同时大幅减小模型体积和推理成本。2025—2026 年,蒸馏技术取得了显著进步——DeepSeek-R1 的蒸馏版本(14B 参数)在数学和代码推理上达到了原始 671B 模型约 85% 的性能,但推理速度提升了 12 倍;OpenAI 的 GPT-4o-mini 通过蒸馏 GPT-4o 的能力,以 1/30 的成本提供了 GPT-4 约 90% 的性能。蒸馏技术的成熟使得企业可以将旗舰模型的能力"浓缩"到可在消费级 GPU 甚至端侧设备上运行的小模型中,大幅降低了部署门槛。
第三条路线是模型量化(Quantization)。量化通过降低模型权重和激活值的数值精度(从 FP32/FP16 降至 INT8/INT4 甚至更低)来减小模型体积和加速推理。2025—2026 年,量化技术从简单的训练后量化(PTQ)演进到量化感知训练(QAT)和自适应精度量化,使得 4-bit 量化模型在大多数任务上的性能损失控制在 2% 以内。例如,Llama 4 Maverick 的 4-bit GPTQ 量化版本可以在单张 NVIDIA A100 80GB GPU 上运行,而原始的 FP16 版本需要至少 8 张 A100。量化与 MoE 的结合("稀疏 + 低精度")正在成为推理优化的黄金组合。
第四条路线是推测解码(Speculative Decoding)。传统的自回归生成模式中,模型每次只生成一个 token,序列化的生成过程严重受限于内存带宽而非计算能力,导致 GPU 利用率极低(通常只有 5%—15%)。推测解码通过引入一个小型"草稿模型"来并行猜测未来多个 token,然后由大模型一次性验证,将有效生成速度提升 2—4 倍而不影响输出质量。Google 的 Gemini 2.5 Flash 和 Anthropic 的 Claude 4 Haiku 均采用了推测解码技术的变体。此外,Medusa、EAGLE 等开源推测解码方案也在快速迭代,使得这一技术不再是闭源模型的专属优势。
推理基础设施的进步同样功不可没。NVIDIA 的 H200/B200 GPU 相比上一代 A100 在大模型推理上实现了 3—5 倍的性能提升;AMD 的 MI300X 以更具竞争力的价格进入推理市场;Google 的 TPU v6e(Trillium)则在大批量推理场景下展现出显著的成本优势。在软件层面,vLLM、TensorRT-LLM、SGLang 等高性能推理引擎通过 PagedAttention、连续批处理(Continuous Batching)和张量并行等优化技术,将单卡的推理吞吐量提升了 5—10 倍。推理优化的终极目标是实现"算法-硬件-系统"三层的协同优化——2026 年的最佳实践已经证明,通过 MoE + 4-bit 量化 + 推测解码 + vLLM 的组合,可以在单台 8 卡 H200 服务器上以 $0.10/百万 token 的成本提供 GPT-4 级别的服务,这一数字在两年前是不可想象的。
三、AI Agent:从概念验证到生产部署的跨越与挑战
AI Agent(智能代理)是 2025—2026 年大语言模型应用层面最重要的范式转移。如果说 LLM 的第一阶段应用是"聊天机器人"(Chat)——用户问一个问题、模型给出一个回答,那么 Agent 则代表了 LLM 应用的第二阶段——模型不再被动回答,而是主动规划、调用工具、执行多步任务并根据环境反馈进行自我调整。简而言之,Agent 让 LLM 从"顾问"变成了"执行者"。
2026 年 Q1,全球 AI Agent 的生态已初具规模。OpenAI 推出了 Operator(浏览器操作 Agent)和 Codex(代码自动化 Agent);Anthropic 的 Claude 4 提供了 Computer Use(计算机操作能力)和 MCP(Model Context Protocol,模型上下文协议);Google 的 Project Mariner 和 Gemini Agent 面向企业办公场景;微软的 Copilot Studio 和 AutoGen 框架则面向企业级 Agent 编排。开源社区方面,LangChain/LangGraph、CrewAI、AutoGPT、MetaGPT 等框架提供了 Agent 开发的基础设施。据 Gartner 数据,2026 年全球已有超过 12000 个企业级 AI Agent 应用投入生产环境,较 2025 年初增长超过 400%。
然而,Agent 的大规模落地面临着一系列严峻挑战。首先是可靠性问题——在多步骤任务中,每一步的错误都会累积和放大。即使单步成功率高达 95%,在一个 20 步的任务中,整体成功率也只有 35.8%(0.95^20)。信悦数科对 246 个企业级 Agent 落地案例的调研显示,仅 34% 达到了预期的 ROI 目标。失败的主要原因包括:工具调用的错误处理不完善(68%)、长流程中的上下文丢失(54%)、边界情况覆盖不足(47%)和缺乏有效的人机协作机制(41%)。
其次是评测与监控的困难。传统软件的测试可以通过确定性的输入输出对来验证,但 Agent 的行为具有天然的不确定性——同一个任务在不同执行中可能走完全不同的路径。2026 年业界尚未形成统一的 Agent 评测标准,企业往往需要投入大量人力进行"人工验收",这严重制约了 Agent 的规模化部署。SWE-bench(软件工程 Agent 基准)、WebArena(网页操作 Agent 基准)和 GAIA(通用 AI 助手基准)等评测集正在逐步被行业采纳,但距离成为"Agent 的 ImageNet"仍有距离。
第三是安全与合规挑战。当 Agent 被赋予执行能力(如操作浏览器、访问 API、修改数据库)后,其潜在风险从"说错话"升级为"做错事"。提示注入攻击(Prompt Injection)在 Agent 场景下的危害被放大——恶意提示可能导致 Agent 执行未授权的操作。2025—2026 年间已有多起 Agent 安全事件被公开报道:包括电商客服 Agent 被诱导给出不当折扣、代码 Agent 误删生产数据库、以及金融 Agent 因工具调用错误导致异常交易等。行业正在探索"防护栏"(Guardrails)技术来应对这些风险——包括输出过滤、权限沙箱、人类审批节点和审计日志等机制。
尽管挑战重重,Agent 的商业价值已在特定场景中得到验证。代码生成 Agent 是当前最成功的应用——GitHub Copilot 已拥有超过 200 万付费用户,开发者使用 Copilot 后代码编写效率提升 30%—55%;Cursor、Windsurf 等 AI 原生 IDE 进一步将 Agent 能力嵌入开发工作流。客服 Agent 是第二大落地场景——企业部署 AI 客服 Agent 后,一线客服人力成本降低 40%—60%,首次响应时间从平均 4 分钟缩短至 15 秒。数据分析 Agent 则通过自然语言查询数据库、自动生成报表和可视化,将数据分析的门槛从"会写 SQL"降低到"会说人话"。
四、全球竞争格局:闭源 vs 开源、中国 vs 全球的双重博弈
2026 年全球大语言模型的竞争格局呈现出两条清晰的对立轴线:闭源与开源之争、中国与全球之争。这两条轴线相互交织,共同塑造着 LLM 产业的竞争态势和商业模式。
在闭源阵营,OpenAI 仍然保持技术领先地位——GPT-5 在综合能力上维持着旗舰地位,o3/o4-mini 在推理任务上遥遥领先。Anthropic 凭借 Claude 4 在安全性、长文本处理和企业级可靠性上建立了差异化竞争优势,Claude 4 的 MCP 协议正在成为 Agent 生态的"事实标准"。Google DeepMind 的 Gemini 2.5 系列则依托 Google 的搜索、地图、YouTube 等数据资产和 TPU 算力优势,在多模态场景中占据独特位置。三家公司的 API 定价策略逐渐形成"梯度化"格局:旗舰模型(GPT-5、Claude 4 Opus、Gemini 2.5 Pro)定价 $5—15/百万 token,性价比模型(GPT-4o-mini、Claude 4 Haiku、Gemini 2.5 Flash)定价 $0.1—0.5/百万 token。
开源阵营在 2025—2026 年经历了质的飞跃,"开源追平闭源"的论调不再是空想。Meta 的 Llama 4 系列(Scout 109B / Maverick 402B / Behemoth 2T)凭借其开放权重策略和强大的性能,成为开源大模型的旗舰。Llama 4 Maverick 在多项基准上达到或超过 GPT-4o 的水平,而其开源属性使得任何组织都可以进行微调和自主部署。除 Meta 外,Mistral(Mistral Large 2)、阿里(Qwen-2.5 系列)、DeepSeek(R1/V3)等也在持续推动开源模型的能力边界。开源模型的核心价值主张是"主权 + 定制"——企业可以完全掌控模型、在自有基础设施上部署、并基于领域数据进行深度微调,这在金融、医疗、政府等对数据主权要求高的行业尤为重要。
中国大模型产业在 2024—2026 年经历了从"百模大战"到头部收敛的深刻整合。2023 年中国一度涌现出超过 130 个大语言模型,但到 2026 年 Q1,真正具备持续迭代能力和规模化用户基础的不超过 15 家。第一梯队包括百度文心大模型 4.5、阿里通义千问 Qwen-2.5、字节跳动豆包、智谱 GLM-5、DeepSeek-R1/V3、月之暗面 Kimi,这六家合计占据了中国 LLM API 调用量的约 78%。第二梯队包括腾讯混元、华为盘古、讯飞星火、MiniMax、零一万物等。市场淘汰的主要原因是资金——训练一个前沿大模型的成本已从 2023 年的 $10M 级别飙升至 2026 年的 $100M—500M 级别,没有持续融资能力或母公司支撑的初创企业难以为继。
中国大模型在技术水平上呈现出"快速追赶、局部领先"的格局。DeepSeek-R1 在数学和代码推理上达到了 o1 的水平,并以开源方式发布,在全球范围内引起了巨大反响;Qwen-2.5 在多语言理解和生成上表现优异;字节豆包以极具竞争力的定价(远低于海外对标模型)快速抢占市场。但在复杂推理能力(GPQA、ARC-AGI 等基准)、超长上下文处理和多模态原生能力上,中国模型与 GPT-5、Claude 4 之间仍存在约 6—12 个月的代差。更深层的差距体现在基础研究和原创性架构创新上——Transformer、MoE、RLHF、DPO 等核心技术范式均由海外实验室率先提出,中国大模型企业在工程化和应用创新上更具优势。
地缘政治因素为中美大模型竞争增添了额外的复杂性。美国商务部 2024—2025 年间持续收紧对华芯片出口管制,NVIDIA H100/H200/B200 等高端 AI 训练芯片对中国实施全面禁运。这迫使中国大模型企业一方面加速国产 AI 芯片(华为昇腾 910C/920、寒武纪 MLU590 等)的替代进程,另一方面在算法层面进行更激进的效率优化——DeepSeek 团队以约 $5.6M 的训练成本实现了接近 GPT-4 的性能,充分体现了"在限制条件下创新"的能力。长期来看,芯片管制将加速中国自主 AI 生态的成形,但短期内对前沿模型训练的算力制约仍然显著。
五、垂直行业落地:金融、医疗、法律、教育、代码五大场景深度解析
大语言模型的商业价值最终需要在垂直行业中兑现。2026 年,LLM 在金融、医疗、法律、教育和软件开发五大行业的落地已从试点阶段进入规模化部署阶段,但不同行业的成熟度和 ROI 表现差异显著。
金融行业是 LLM 企业级应用最活跃的领域。据麦肯锡估算,2026 年全球金融机构在 LLM 相关技术上的投入约 280 亿美元,主要应用场景包括:智能研报生成(分析师效率提升 40%—60%)、客户服务自动化(私人银行和财富管理的客户交互成本降低 35%)、合规与反洗钱文档审查(处理速度提升 8—12 倍、准确率从人工的 82% 提升至 94%)、量化交易策略生成(基于自然语言描述自动生成回测代码)。摩根大通的 LLM Suite、高盛的 GS AI、彭博的 BloombergGPT 2.0 是该领域的标杆产品。中国金融机构中,工商银行、招商银行和蚂蚁集团在 LLM 应用上走在前列。金融行业 LLM 的最大挑战是"幻觉"问题——在需要精确数字和合规表述的场景中,即使 1% 的事实性错误也可能导致严重的法律和合规风险。业界通过 RAG(检索增强生成)、事实性校验和人机协作流程来缓解这一风险。
医疗行业的 LLM 应用增长最快但门槛最高。2026 年,Google 的 Med-Gemini、微软/Nuance 的 DAX Copilot 和国内的医渡云等产品已在临床辅助决策、医学影像报告生成、电子病历结构化和药物研发等场景取得实质性进展。Med-Gemini 在美国医学执照考试(USMLE)的模拟测试中达到 91.1% 的通过率,超越了大多数医学生的表现。然而,医疗 LLM 的合规壁垒极高——在中国,医疗 AI 产品需要获得国家药监局(NMPA)的三类医疗器械注册证,审批周期通常为 18—24 个月。此外,患者数据隐私(HIPAA/GDPR/中国《个人信息保护法》)和临床责任归属问题也是制约医疗 LLM 大规模推广的关键因素。
法律行业被认为是 LLM 的"天然适配场景"——法律工作的核心是理解、检索和生成文本,这恰恰是 LLM 的强项。2026 年,Harvey AI(获 OpenAI 投资)、CoCounsel(由 Thomson Reuters 推出)和中国的幂律智能等法律 AI 产品已在合同审查、法律研究、诉讼文书生成和尽职调查等场景实现商业化。美国 AmLaw 200 律所中已有超过 65% 部署了至少一个 LLM 工具;中国方面,北京、上海和深圳的 TOP 50 律所中约 40% 开始试用法律 LLM 产品。法律 LLM 的核心价值在于将初级律师 8—10 小时的合同审查工作压缩到 15—30 分钟,准确率达到高级律师水平的 88%—92%。
教育行业的 LLM 应用正处于"爆发前夜"。Khan Academy 的 Khanmigo(基于 GPT-4)、Duolingo Max(基于 GPT-4)和国内的学而思 AI 学习伙伴等产品代表了"AI 导师"的早期形态——根据学生的学习进度和薄弱环节提供个性化的解释、练习和反馈。据 HolonIQ 数据,2026 年全球教育 AI 市场规模约 64 亿美元,其中 LLM 相关产品占比约 35%。教育 LLM 面临的独特挑战是"正确性要求的绝对化"——在教育场景中,错误的知识传递可能对学生产生长期负面影响,这使得"幻觉"问题在教育场景中比在其他场景中更难被容忍。
软件开发是 LLM 渗透率最高、ROI 最清晰的垂直行业。GitHub Copilot 已拥有超过 200 万付费用户和 7.7 万企业客户;Google 报告其超过 25% 的新代码由 AI 生成;亚马逊声称其内部 AI 代码工具已节省了相当于 4500 个开发者年的工时。2026 年 AI 代码工具的竞争已从"代码补全"升级到"全流程 Agent"——Cursor、Windsurf、GitHub Copilot Agent Mode 等产品允许开发者用自然语言描述需求,AI 自主完成从代码编写、测试生成、Bug 修复到 Pull Request 创建的全流程。在 SWE-bench Verified(真实 GitHub Issue 修复基准)上,最佳 Agent 的解决率已从 2024 年初的 13% 提升至 2026 年 Q1 的 72%。软件开发 Agent 的成功很大程度上得益于软件工程本身具有良好的可验证性——代码要么能编译通过并通过测试,要么不能,这为 Agent 的自我纠错提供了天然的反馈循环。
六、未来展望:2026—2030 年大语言模型的六大趋势
基于对技术演进规律、产业竞争态势和企业落地实践的系统研究,信悦数科研究团队对 2026—2030 年大语言模型的发展提出以下六大趋势判断。
趋势一:从"通用大模型"到"专用推理引擎"的分化。2026 年后,LLM 将不再是"一个模型解决所有问题"的范式。取而代之的是"模型路由"架构——一个轻量级的路由模型根据任务类型自动选择最合适的专用模型:需要深度推理的数学题发送给推理专用模型(如 o4-mini),需要快速生成的客服对话发送给轻量对话模型(如 Gemini Flash),需要多模态理解的任务发送给多模态专用模型。这种"模型混搭"(Model Routing / Mixture of Models)策略可以在保证质量的同时将成本降低 70%—85%。
趋势二:端侧大模型(On-Device LLM)的崛起。随着苹果 Apple Intelligence、三星 Galaxy AI、高通 AI Engine 等端侧 AI 能力的成熟,越来越多的 LLM 推理将在手机、PC 和 IoT 设备上本地完成,而非依赖云端 API。2026 年底,具备 7B—13B 参数 LLM 本地运行能力的智能手机已超过 10 亿台。端侧模型的优势在于延迟极低(<100ms)、无需网络连接、数据完全私密。预计到 2028 年,约 40% 的 LLM 推理将在端侧完成。
趋势三:Agent 生态的平台化与标准化。随着 MCP(Model Context Protocol)、OpenAI 的 Function Calling 标准和 Google 的 A2A(Agent-to-Agent)协议的推广,Agent 之间的互操作性将大幅提升。未来的 AI 应用将不再是孤立的单体 Agent,而是由多个专用 Agent 协作组成的"Agent 团队"——类似于微服务架构对单体应用的改造。企业将构建和运营自己的"Agent Fleet"(Agent 舰队),通过统一的编排层进行管理和监控。
趋势四:合成数据成为训练的主要数据源。随着自然产生的高质量文本数据逐步耗尽,合成数据——由大模型自身生成的训练数据——将成为未来模型训练的核心资源。2026 年,业界已经在数学推理(通过蒙特卡洛树搜索生成推理路径)、代码生成(通过编译器验证筛选正确代码)和指令遵循(通过 Constitutional AI 自动生成偏好数据)等场景中验证了合成数据的有效性。预计到 2028 年,前沿模型训练数据中合成数据的占比将超过 60%。合成数据的核心挑战在于避免"模型坍塌"(Model Collapse)——用模型生成数据再训练模型可能导致分布退化,业界通过引入多样性奖励和人类数据锚定来缓解这一问题。
趋势五:AI 安全与治理从"行业自律"走向"全面监管"。欧盟《人工智能法案》(AI Act)已于 2025 年 8 月全面生效,将基础模型(GPAI)纳入监管范围,要求模型提供商进行透明度报告、对抗性测试和版权合规。中国《生成式人工智能服务管理暂行办法》和后续的《人工智能法》草案也在持续完善监管框架。美国则采取行政令与行业自律相结合的路径。2026—2030 年,AI 治理将从"软法"向"硬法"转变,模型能力评估(Model Evaluation)、红队测试(Red Teaming)和安全审计将成为模型发布的标准流程。这对大模型企业意味着合规成本的显著上升,同时也为 AI 安全创业公司创造了巨大的市场机会——AI 安全市场规模预计从 2026 年的 18 亿美元增长至 2030 年的 110 亿美元。
趋势六:AGI(通用人工智能)的路径争论将在 2028 年前迎来关键验证窗口。OpenAI、DeepMind、Anthropic 等领先实验室均已公开表示"AGI 可能在 2027—2030 年实现"。但对于 AGI 的定义和达成路径,行业远未达成共识。一派观点认为继续 Scale Up 当前的 LLM 架构,辅以推理模型和 Agent 能力,足以达到 AGI;另一派观点认为当前的 Transformer 架构存在根本性局限(如缺乏持久记忆、无法进行真正的因果推理和规划),需要全新的架构突破。无论哪种路径最终成功,2026—2028 年间的技术进展将为这场争论提供决定性的实证证据。对于企业而言,AGI 的具体时间表并不重要——重要的是,即使不达到 AGI 水平,2026 年的 LLM 能力已经足以在大量任务中提供超越人类平均水平的表现,企业应当立即行动而非等待"完美的 AGI"。
总结与展望:信悦数科认为,大语言模型在 2026—2030 年将经历从"模型能力竞赛"到"应用价值兑现"的关键转折。短期来看(2026—2027),最大的价值创造机会在于利用推理成本的骤降和 Agent 框架的成熟,将 LLM 能力嵌入到企业的核心业务流程中——代码开发、客服自动化、合规审查和数据分析是 ROI 最清晰的四个切入点。中期来看(2027—2028),端侧模型和 Agent 生态的成熟将催生全新的应用形态,AI 从"工具"升级为"协作者"。长期来看(2028—2030),LLM 将成为数字世界的"操作系统级"基础设施,嵌入到几乎所有的数字产品和服务中。对于企业决策者而言,核心信息只有一条:大模型的能力已经"够用"了,现在是投入精力解决落地问题——数据准备、工程化集成、组织变革和安全治理——的最佳时机。等待只会拉大与先行者的差距。